QUIC中文翻译
翻译过程一些心路历程:
距离上次完整翻译一篇文章已经好几年了,那还是本科毕设用的文章翻译,那时候还能用谷歌翻译,现在也又能了……….
词汇量还是太差。。
对于翻译,并不用把每句话都翻译出来,整段话意思一致就可以了。
对于某些名词,也不需要完完全全翻译。

Deserted..
@(Network)[tcp, 慢启动]
[1] rfc-5681
[2] tcp-abc-rfc
[3] rfc-3465
[4] rfc-3742
慢启动和拥塞避免,主要是用于拥塞控制中拥塞窗口增长的维护。
根据阈值,拥塞控制其实分为两部分,小于阈值的慢启动阶段,大于阈值进入拥塞避免阶段。
慢启动作为拥塞控制的一部分,我觉得其名字取的比较具有混淆性。个人理解的慢启动分为两种,一种是拥塞窗口小于阈值时候正常的一个指数增长的过程,这个过程中的拥塞窗口不会重置,会持续增长,还有一种是与快速恢复对应的慢启动重新启动,这种时候会将拥塞窗口重置为1,并重新开始指数增长。这么理解的原因如下:
在文档中描述快速恢复时,当收到三个重复ack时候,这时候可能并不是实际丢包,可能是因为链路问题,较晚到达接收端。
因此,个人理解,老版本上收到三个重复ack认为丢包,进入丢包处理,重置了拥塞窗口,在非重复ack到来后,拥塞窗口仍然需要从零开始指数上升,而对于快速恢复而言,其只进入拥塞避免阶段,拥塞窗口只是进行一定修正,在非重复ack到来后,仍然能根据阈值来决定是否执行非重启的慢启动,这时候恢复速度相较于严格的丢包处理快了不少。
由于tcp对于丢包的容忍极低,一旦丢包发生,就会进入严格的拥塞处理,而RTO是丢包主要判断依据,因此快速重传也是针对tcp对于丢包容忍度低的一个修正,避免进入RTO,直接影响传输性能。
本章主要基于reno的拥塞控制。下文中的代码均基于linux kernel 2.6.32版本,直到linux kernel 4.9-rc8之前的版本,tcp整体并没有太大变化。本文不分析frto相关内容。
由于文档描述上是直接给出一个计算过程,如慢启动阶段的指数上升,和代码直观上看略有不同,因此这里需要先缕清楚整个的调用链,能更好的描述整个拥塞控制的过程。
tcp的拥塞主要是基于定时器(RTO)和ack的,因此主要处理函数都以tcp_ack为起点。这里不分析整个tcp_ack函数,仅分析常规调用链。
整体入口如下:
|
|
tcp reno注册到拥塞控制框架中的是tcp_reno_cong_avoid函数。
其代码较为简单,只是其中多了一部分tcp-abc的拥塞避免算法,其慢启动实现在tcp_slow_start中,可以参考[rfc-3465][tcp_abc]。大体是用已经确认的byte大小来作为拥塞控制的计算,在慢启动阶段会更加激进,但是可能会带来更大的burst。
|
|
慢启动里面额外涉及两篇rfc,rfc-3742和tcp_abc。
其中snd_cwnd_cnt为线性增长器,只有当线性增长器大于一个窗口大小时,其才会将发送窗口增加,即其单位为1/snd_cwnd,后续还会在拥塞避免代码中见到。
刚开始看代码时对下面那个循环并不是很理解,不理解为什么++是指数增长,直到放到整个调用栈上看,其具体流程如代码注释中所写,为指数增长的过程。
|
|
拥塞避免的代码比较简短,注意2.3中所写的,snd_cwnd_cnt为线性增长器,其单位为1 / w。在reno调用中,这里的w也为snd_cwnd窗口大小。即每一个ack只增加1 / snd_\cwnd大小的窗口。
|
|
对tcp_slow_start的改动不算是4.9的,早在3.18之前就已经改变了,使用的已经不是之前的snd_cwnd_cnt,而是采用tcp-abc算法来进行慢启动。
慢启动仍然使用类似tcp-abc的实现机制,不过其并不以byte作为单位,而是以MSS作为单位进行处理。1234567891011121314151617181920212223/* Slow start is used when congestion window is no greater than the slow start * threshold. We base on RFC2581 and also handle stretch ACKs properly. * We do not implement RFC3465 Appropriate Byte Counting (ABC) per se but * something better;) a packet is only considered (s)acked in its entirety to * defend the ACK attacks described in the RFC. Slow start processes a stretch * ACK of degree N as if N acks of degree 1 are received back to back except * ABC caps N to 2. Slow start exits when cwnd grows over ssthresh and * returns the leftover acks to adjust cwnd in congestion avoidance mode. */u32 tcp_slow_start(struct tcp_sock *tp, u32 acked){ // 使用确认的包数(其中可能包括sack的确认,或者重传数据的确认都加上) // 来更新窗口值,而不是之前的byte。 // 在函数tcp_clean_rtx_queue中有更新对应的delivered。 // 其更新的值貌似和MSS有关系。 u32 cwnd = min(tp->snd_cwnd + acked, tp->snd_ssthresh); // 当acked仍然有值,说明超过阈值,处理完slow start后还会进行congestion avoid的处理。 acked -= cwnd - tp->snd_cwnd; tp->snd_cwnd = min(cwnd, tp->snd_cwnd_clamp); return acked;}
拥塞避免上和老版本类似,也使用到了线性增长器,但是涨幅比之前版本较大,并不是以1为计数,而是以acked,即已经确认的MSS个数据片作为单位。
|
|
@小刘1悦
@(Network)[tcp, congestion control]
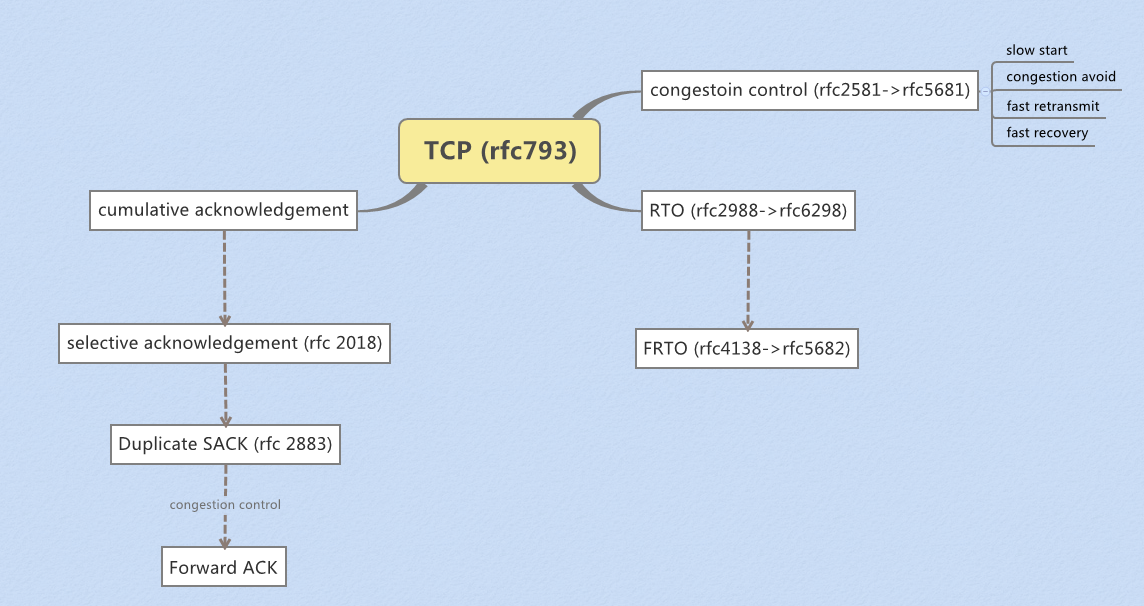
本文主要记录阅读linuxtcp文章,其第二章中主要介绍了TCP拥塞控制的基础和一些发展历程,这里作为整理。
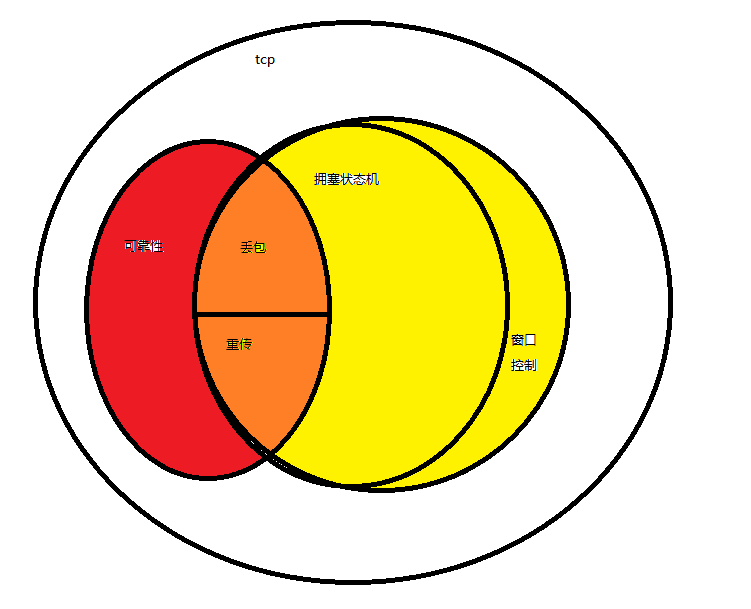
个人理解,TCP的拥塞分为两部分,一部分是窗口值变化,慢启动和各种拥塞避免算法,这部分只尝试控制发往网络中的包的数量(拥塞窗口),但是他并不处理是否丢包,是否应该重传,或者快速重传等;另一部分是TCP逐渐支持的一些机制,可以使tcp更好的进行网络状态的估计,不同的网络状态会对第一部分进行反馈,这部分属于框架级别(其实丢包重传和拥塞控制本身并没有完全相关性(比如固定丢包的链路,无线网络等),但是由于长久以来的拥塞控制是基于丢包的,因此丢包作为网络拥塞状态判断,耦合在TCP的拥塞控制中,而由于丢包对拥塞控制的影响是毁灭性的,因此也在重传上做了较多的处理,来避免因为一些意外的丢包造成的影响,或者是提早避免因为网络拥塞导致的丢包)因此对应的tcp内核中,一部分对应的拥塞控制状态机,这里处理了所有tcp所支持的机制,如SACK,DSACK,FRTO等网络估计的基础,而拥塞避免则会根据猜测的网络状态进行合理控制。
[TOC]
[1] linux_tcp
[2] SACK
[3] Duplicate SACK
[4] Duplicate SACK ppt
[5] FACK
[6] FRTO-4138
[7] FRTO-5862
[8] FRTO-细节
[9] An Enhanced Recovery Algorithm for TCP Retransmission Timeouts
TCP拥塞控制算法主要由发送端通过拥塞窗口(cwnd)来控制。最开始主要有两个拥塞控制的方法,通过阈值ssthresh来作为两种窗口增长的临界标志。
重传可能被重传定时器RTO触发,RTO一旦超时,表明某个包丢失,对于TCP而言,丢包意味着网络产生拥塞,因此此时会把拥塞窗口降低到最小值(1个segment大小)。因此丢包是非常严苛的拥塞条件,一旦丢包发生,对整个传输效率会造成极大的影响。
In addition, when RTO occurs, the sender resets the congestion window to one segment, since the RTO may indicate that the network load has changed dramatically.
This is done because the packet loss is taken as an indication of congestion, and the sender needs to reduce its transmission rate to alleviate the network congestion.
由于RTO本身对于TCP性能而言非常严苛,因此RTO使用的定时器时间是否能准确反映网络实际传输情况对于TCP而言非常重要。比如链路RTT突然增加了,但是用于RTO的RTT仍然是之前的小值,这样可能会导致数据虽然没有丢包,但是交往较慢,RTO触发过于频繁,再由于丢包对于TCP的影响,会导致TCP窗口衰减剧烈。
但是TCP对于普通包和重传包使用相同的sequence number,因此当ack到来时,无法区分这个ack对应的是普通包的还是重传包的,因此此时用这个ack的时间戳选项来计算链路RTT可能会导致各种问题。
因此当前使用的RTT计算公式一般是smooth rtt计算。
由于丢包属于一类重大事故,因此TCP中总是需要尝试提前发现,在其形成重大事故(重置cwnd)前将其提前识别。因此当接收端收到乱序包时,会发送期待的包的序号ack,当发送端收到两个重复的ack时,会发现出现乱序(状态机中的Disorder),并尝试进行重传来恢复这个包,以免RTO超时触发。当发送端收到三个重复的ack时,会进入快速恢复(状态机中的Recovery),认为网络可能存在一定的拥塞,会降低拥塞窗口(但是不会像RTO触发以后那样激进)。两种状态下,都会恢复认为丢失或者乱序的包,直到收到非重复的ack为止。
由于TCP本身并无法感知到整个网络链路的质量,因此基本是基于自己的算法和丢包反馈来进行拥塞判断,本身存在一定的局限性。
后来的一些路由器在处理数据包,可能可以感知到网络是否真正拥塞,当路由器感知到拥塞时,会通过设置TCP标志位的ECE给TCP,TCP发送端收到带有ECE的ack时会进入拥塞状态(状态机中的CWR),同时发送一个携带标志位CWR的包给接收端,表示自己当前正在衰减拥塞窗口。
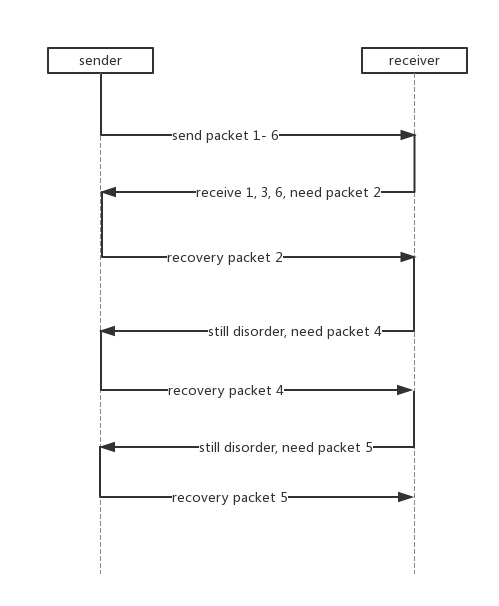
由于进入乱序或者快速重传后,在一个RTT之内只能处理一个异常包(不会发送新的包直到新的ack到来,但是当丢包是不连续的若干个,恢复完后仍然会进入对应状态,单独处理下一个乱序丢包,如发送端发送1-6,接收端先收到1,3,6,这时候发送先恢复包2,恢复完包2收到ack发现乱序,请求包4,发送端再恢复4,恢复后发现仍然乱序,请求包5,再次单独恢复包5),因此在恢复阶段严重影响吞吐量。
SACK并没有打破原有的ack机制,只是在其ack机制上,在TCP option字段中附加了额外信息。4
例子如下图: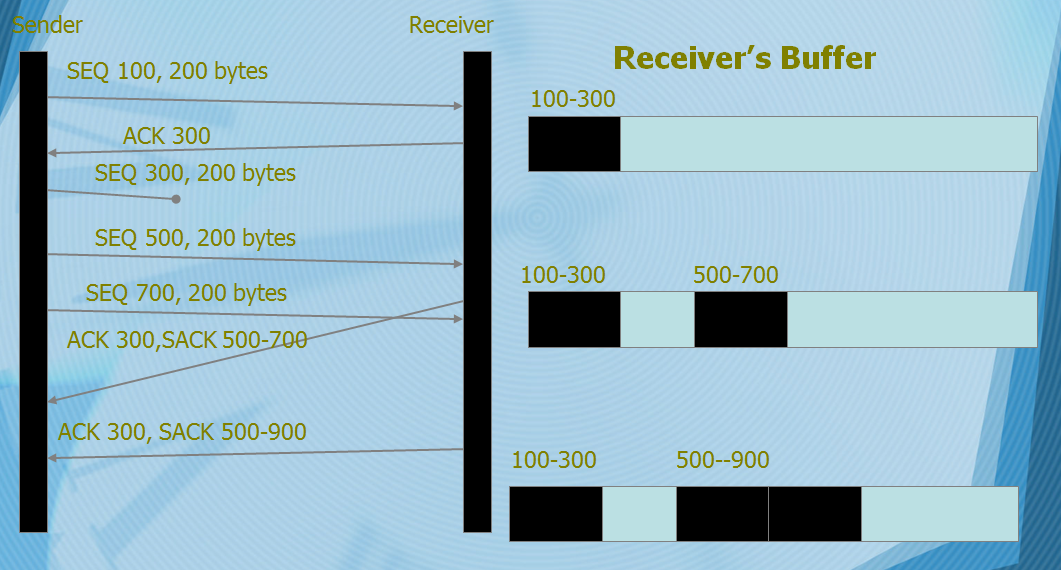
Multiple packet losses from a window of data can have a catastrophic effect on TCP throughput.
SACK does not change the meaning of ACK field.
注: SACK附加在TCP option字段中,option字段最多只有40字节,因此SACK最多包含四个区间。
注2: SACK必须接收和发送端都支持才可以正常使用。
SACK在rfc 2018定义的时候,并没有声明其收到两个相同的包以后的处理。D-SACK会使接收端发送重复块的信息给发送端。
简单流程如下:
当DSACK激活时,最后一个ACK中的SACK第一个区域为重复区域,不同于普通SACK,它是已经收到的区域的一个子区间,每个重复块只会上报一次。
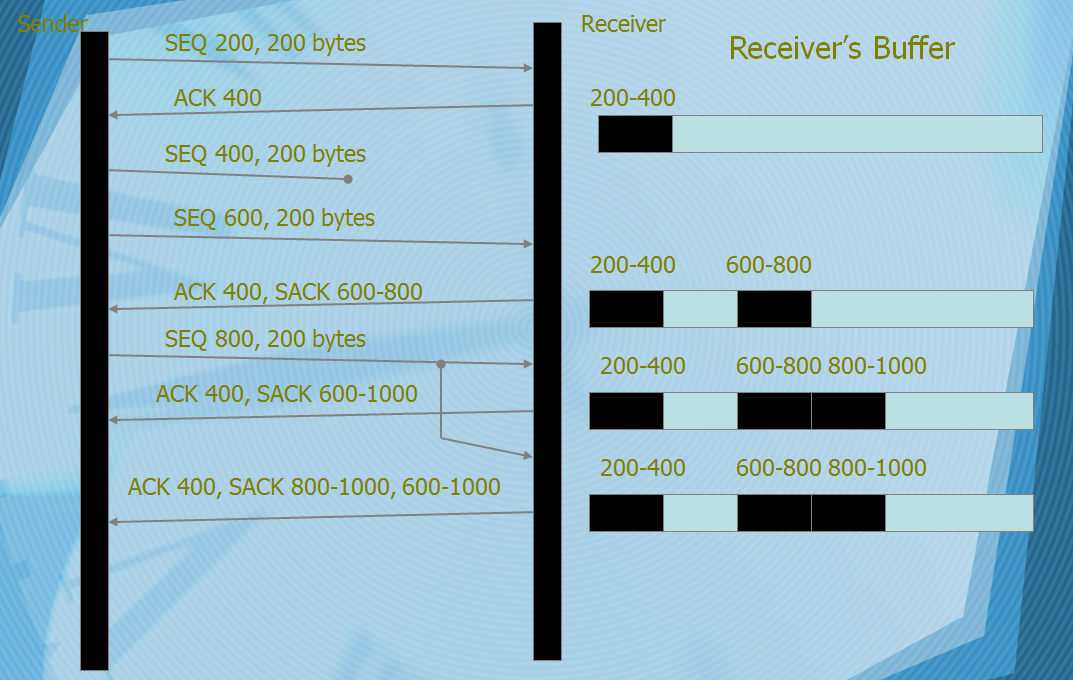
Forward Acknowledgement是基于SACK的相关的拥塞控制算法。
当拥塞发生时,此时已经发生丢包,这时候会引入新的变量fackets_out来统计SACK中的数据量,并根据当前已经发送的数据量una和重传数据量retran来估算本条连接实际在网络中的包数量(总包数 - 已经ACK的数量 + 重传包)。并根据这个数值和拥塞窗口进行比较,如果当前网络中的包数量小于拥塞窗口,说明仍然可以往网络中发送部分数量的包。
这种算法本质上是对网络中的包数量进行更精确的估计,结合DSACK,可以更精准的进行判断,可以在恢复阶段依旧保持一定的速率,在处理乱序包的时候可以比传统TCP更加激进。
当网络链路存在一些突发的特殊场景时,可能会触发超时定时器,由于TCP对于丢包的处理异常严格,可能会造成链路质量下降。
可能的一些场景:
稳定的链路上可能也有一些原因导致某些包及其重传老是失败。
First, some mobile networking technologies involve sudden delay spikes on transmission because of actions taken during a hand-off.
可能造成的一些影响:
当虚假超时触发后,可能造成虚假重传,当过多虚假重传发生后,对应的ack回来时可能会触发虚假的快速恢复,如下图,第二次虚假的快速重传是由于第一次虚假RTO超时导致重传发送了重复包导致。
However, if the RTO occurs spuriously and there still are segments outstanding in the network, a false slow start is harmful for the potentially congested network as it injects extra segments to the network at increasing rate.
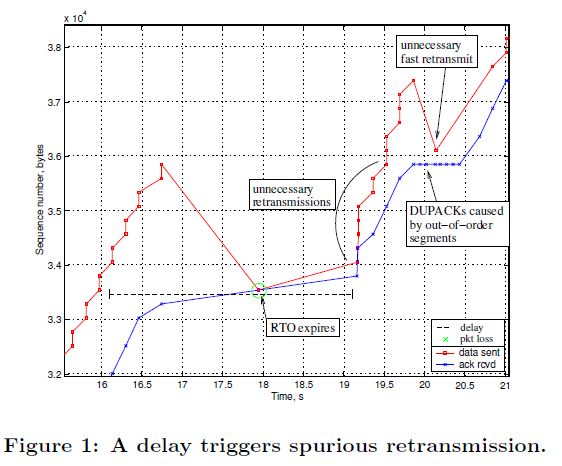
FRTO会在RTO超时后,不会类似传统TCP的超时机制,会额外根据后续两个ACK与当前未确认的最小包进行比较,根据这个结果判断当前RTO是否在安全范围内。
如果收到的是未确认的包之后的包,则可能是因为网络原因导致的延迟,可以进入恢复状态。
如果收到的是重复的ack,则认为这个包确实已经丢失,进入丢包状态。
简单用图画出之间衍生的关系。
涛哥分析的好有道理

下一期涛哥应该要带来猜奥秘的模型了吧!
以下代码待验证。12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485using namespace std;class tree { public: void build_tree (int dragon, int damage) { vector<int> in; in.push_back (30); for (int i = 1; i < dragon + 1; i++) { in.push_back (2); } build_tree_1 (in, damage, 1.0); } bool result_match (vector<int> &in) { int cnt = 0; for (int i = 1; i < in.size (); i++) if (in[i] != 0) cnt++; return cnt == alive; } void build_tree_1 (vector<int> &in, int damage, float p) { int count = 0; float new_p = 0.0; for (int i = 0; i < in.size (); i++) cout << in[i] << ","; cout << "Prob " << p << " else damage " << damage << endl; if (damage == 0) { if (result_match (in)) result += p; return; } for (int i = 0; i < in.size (); i++) { if (in[i] != 0) count++; } if (count == 0) return; new_p = p / count; count = 0; for (int i = 0; i < in.size (); i++) { /* A dead dragon. */ if (in[i] == 0) continue; in[i]--; build_tree_1 (in, damage - 1, new_p); in[i]++; } } tree (int dragon, int damage, int _alive) : alive (_alive) { result = 0.0; build_tree (dragon, damage); } float get_result () { return result; } ~tree () { } private: int alive; float result;};int main (){ tree t (3, 8, 1); cout << t.get_result () << endl; return 0;}
缺失模块。
1、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
2、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: true
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true