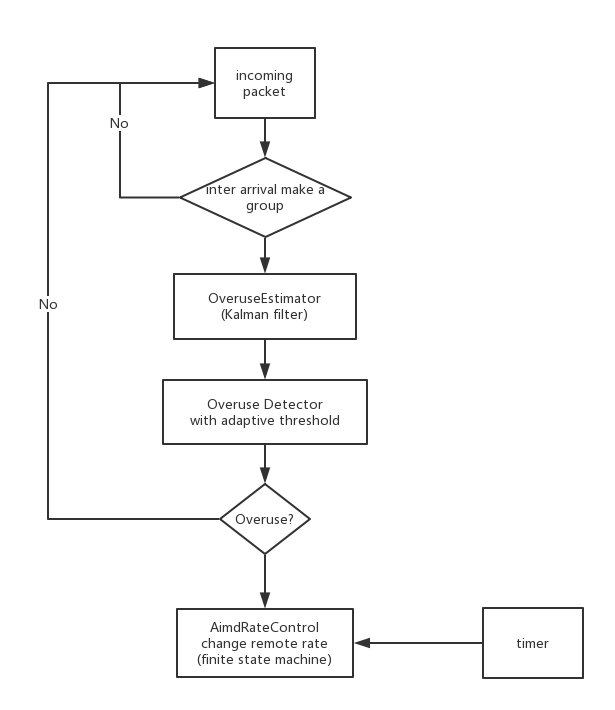
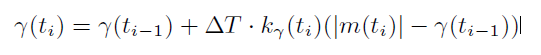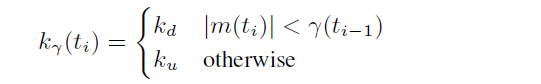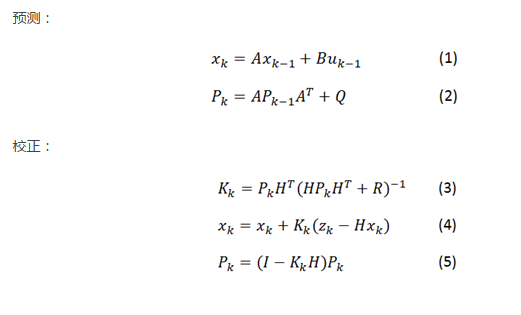网络传输协议
网络传输目标
- 高吞吐量,尽量跑满实际链路带宽。
- 避免污染物理链路,防止过量数据包在物理链路中,导致其他数据包无法发送,反而造成带宽利用率的低下。
- 不同流之间可以公平的共享网络资源。
可靠传输与不可靠传输
确认方式
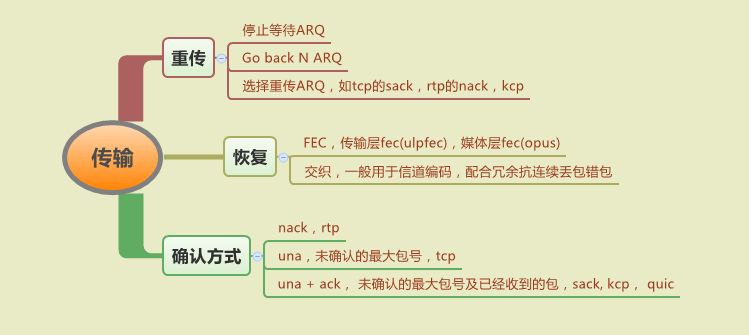
确认方式主要有三种:
- 被动拉包nack:rtp使用方式,主要用于非可靠传输,接收端可以选择性进行丢包恢复。
- unacknowledge:tcp默认使用方式,表示当前未确认的最大包号,但是使用这种方式,由于没有其他信息,在重传请求的时候只能依赖停止等待ARQ或者go back N ARQ方式进行重传,重传效率低下,容易影响丢包或者乱序时候的整体吞吐量。
- acknowledge:表示当前已经收到的包,一般结合unacknowledge使用,类似tcp中的SACK,quic的ack + stop waiting,kcp。
可靠丢包恢复
由于网络丢包问题(包括随机丢包或者是拥塞丢包)存在,可靠传输需要重传丢失报文,在实时性上具有较大的局限性,大部分非实时传输协议都属于可靠传输协议。
不可靠传输可以选择性的丢弃一些非关键数据,减少在丢包的重传,牺牲可靠性获取更高的实时性,常见的有rtp/rtcp协议。
可靠传输需要对丢失的报文进行恢复,常见的恢复方式有以下几种:
- 停止等待ARQ:当丢包发生时,只重传丢失的包,且在丢失包恢复前不会重新传送新的报文,这种方式实现容易,但是这种重传方式对吞吐量的损害非常大,特别是当RTT特别高,一个包来回时间间隔特别长的时候。
- 选择重传ARQ: TCP的SACK方式,需要提供额外的丢包信息,可以对若干个不连续的包进行对应的重传,TCP的SACK会在TCP option字段中增加ack之后的已经收到的报文段,这种重传方式中,可以获得更高的吞吐量,但是实现上较为复杂,需要额外维护一个队列,具有一定的性能损耗。
- 被动拉包: 被动拉包与选择重传ARQ其实相同,只是由于RTP没有ack报文,因此当丢包发生时,且需要进行可靠传输时,会使用RTCP的NACK报文来向发送端请求重传。[gstrtpjitterbuffer][代码分析]
不可靠丢包恢复
以上为发送端需要重传才能进行恢复,下面两种则为发送端不需要重新发送丢失报文,通过一些方法来进行恢复,但是这种恢复本身并不是一定可靠的,因为恢复可能会失败。
- FEC: 前向纠错编码,增加了冗余数据,当丢包发生时,可以使用冗余数据和正常接收到的原数据进行计算,将丢失的数据包进行恢复。webrtc中使用ulpfec(red封装),ulpfec认为数据包的不同部分重要程度不同,对重要部分进行高冗余保护,对重要程度比较低的数据部分进行较少的冗余保护。下述例子中,认为包的前70bytes是重要数据,每两个包就进行一次fec,而中间90bytes重要程度较低,四个包产生一个fec。
|
|
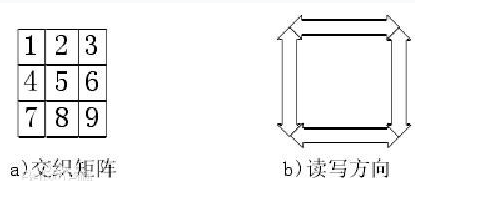
- 交织: 交织在高层协议中出现比较少,更多出现在无线网络的物理层中信道编码,具有较强对抗连续错包丢包的能力。如下图,当输入顺序为三个数据包的九个分片(1、2、3)、(4、5、6)、(7、8、9)时,写到对端的顺序发生相应的改变,为1、4、7、2、5、8、3、6、9,假设网络出现偶然的丢包,这时候中间三个包丢失,即2、5、8丢失,此时三个包都丢了一个分片,可以利用包内的冗余校验算法,对丢失的分片进行恢复,此时仍然可以将三个包完整的恢复出来,不需要进行重传。
TCP
TCP是可靠传输协议,其可靠性主要由ack来保证,接收端会向发送端发送ack报文来告知发送端是否丢包。
TCP会尝试去估计可用带宽的阈值(ssthread,bbr例外),并将码率维持在阈值附近,缓慢增长。
TCP的目标
除了网络传输协议的目标之外,由于tcp基于ack的应答模式,其还有一些新的目标需要实现。
- RTT公平性:由于tcp窗口增长是基于ack的,因此RTT较大的流增长速率较慢,达到平衡点时RTT大的流码率较低。
- 高吞吐量:尽量高的保持网络吞吐量,即使在一些异常的场景下,也应该尽量保持较好的吞吐量(特别是丢包)。
- 公平性:不同TCP流共享网络资源。
- 拥塞避免:避免网络中存在过量报文。
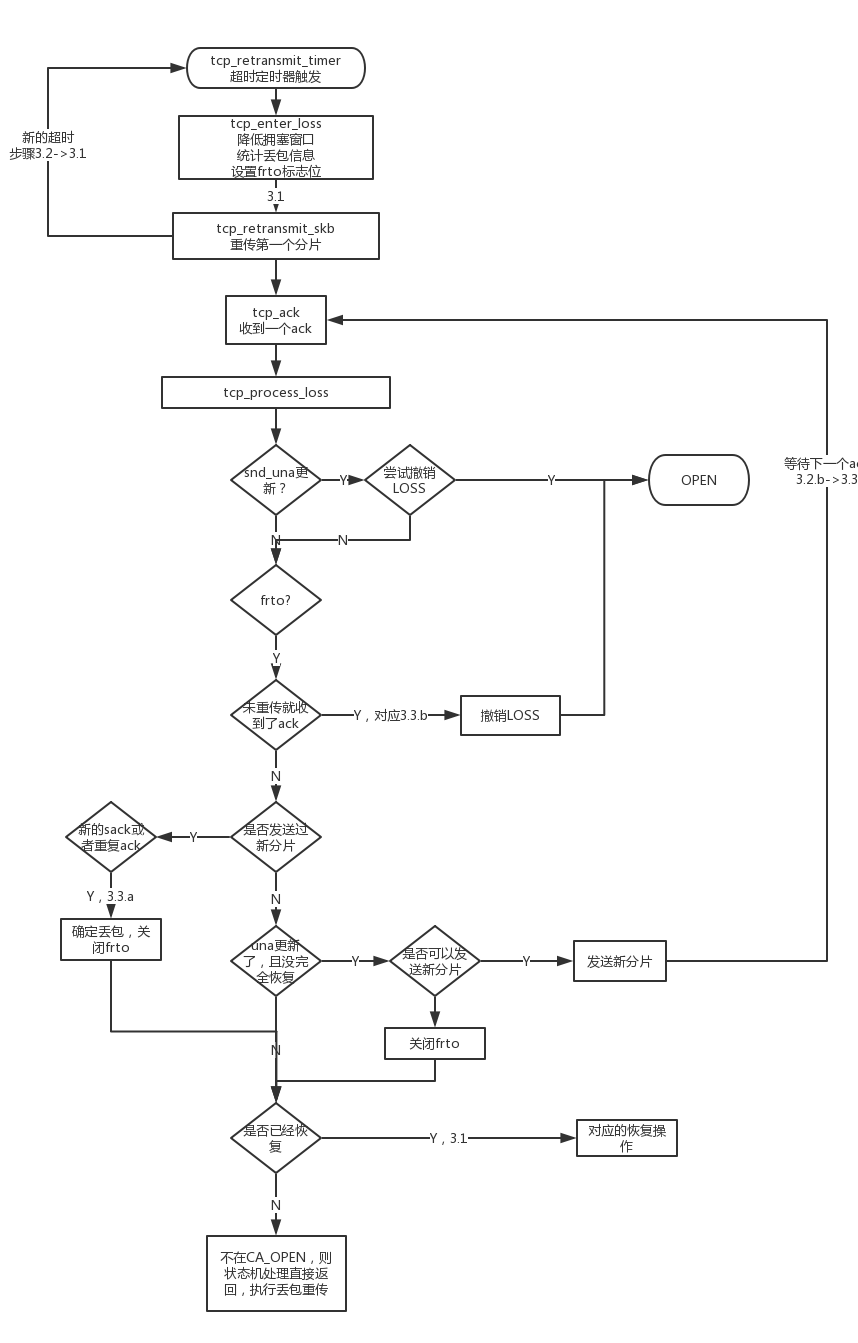
TCP拥塞控制模块
拥塞控制框架
内核中的拥塞控制分为两部分,一部分是属于框架级别,包含了拥塞控制状态机的状态转换,也包含了不少新的patch,这一部分主要的目的是提高TCP整体的吞吐量,包括对可能丢包的场景的处理。
- 乱序判断:两个ack到来时会认为存在乱序,此时会稳住整体的发送窗口。
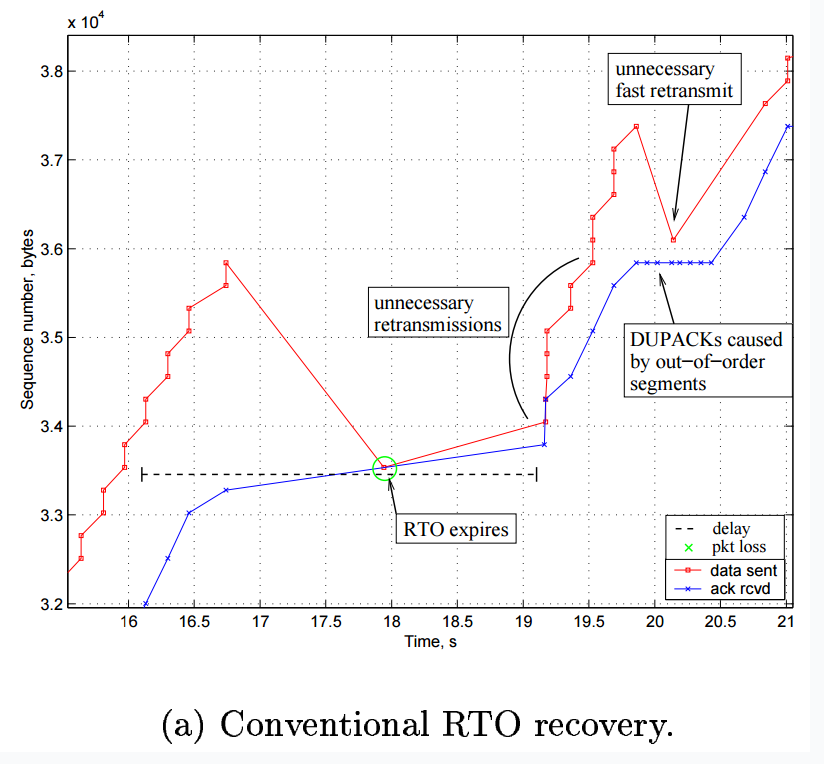
- 快速重传和快速恢复:由于默认的丢包状态对TCP链路阈值的估计影响巨大,因此要尽量在RTO触发之前尝试发现一些可能的丢包,当三个重复ack到来时会认为网络存在可能拥塞,会尝试先降低吞吐量,防止持续大量数据影响实际链路。
- SACK:解决停止等待ARQ造成的吞吐量下降。
- DSACK:在SACK的第一个块中包含了重复收到的块号。
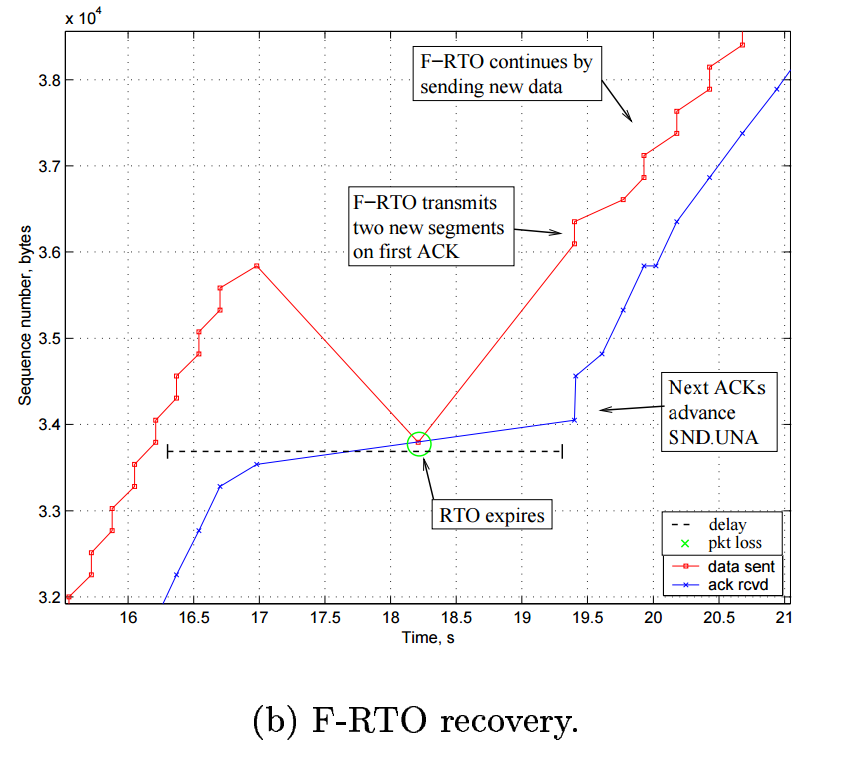
- FRTO:bugfix,修复DSACK会导致的额外快速恢复。
- PRR:比例速率衰减,对拥塞控制的衰减进行控制。
- ER:early retransimission,提早进行重传,尽量避免丢包状态,也可以避免进入快速恢复。
- TLP: 针对early retransimission的tail loss probe。
拥塞避免
第二部分为拥塞避免模块,这个模块控制拥塞窗口的变化,这个模块的主要目的是为了避免对网络中注入过量的数据包导致物理链路污染。
但是,使用不同的拥塞控制算法有以下几个实现上的难点:
- 算法公平性:在使用相同的拥塞控制算法时,流间公平性可以得到保证,但是使用不同的拥塞控制算法时,公平性会成为最复杂的问题,特别是以延迟为判断条件的拥塞控制算法在对抗以丢包为判断条件的拥塞控制算法时。
- 拥塞判断:传统TCP默认使用基于丢包的拥塞判断条件,早期时候路由器中没有buffer存在,当链路拥塞时,路由器会丢弃报文,但是随着技术发展,路由器中设置了buffer,因此当链路拥塞发生时,路由器还缓存包,但是对于主机无法感知,仍然以较高的速率(慢启动)进行发送,从而污染了物理链路。但是如果使用延迟作为判断条件,则会有算法公平性问题,容易被基于丢包的拥塞控制算法饿死。
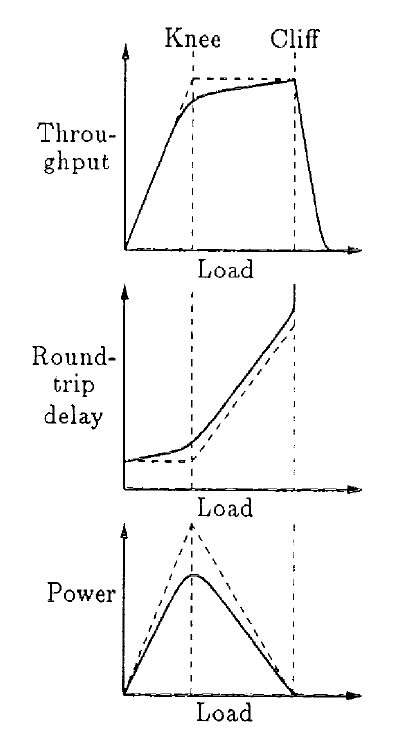
- RTT公平性:不同流的rtt不同,但是tcp基于ack进行拥塞窗口变化,因此RTT小的流窗口增长速度快于RTT大的流(hystart in cubic)。
拥塞避免算法分类
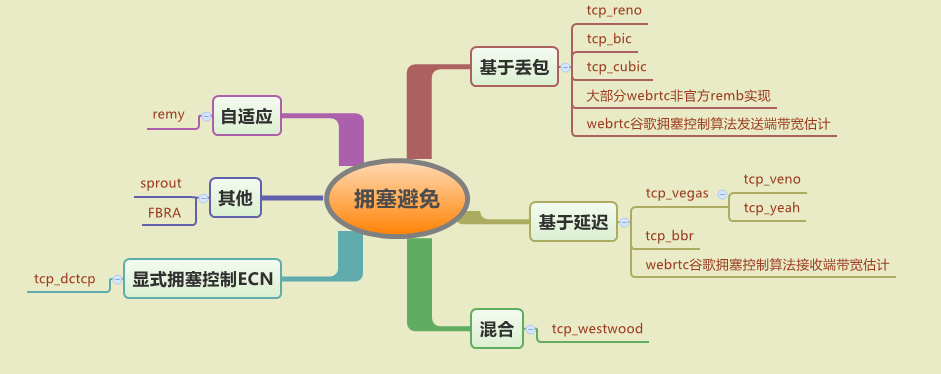
拥塞避免算法依据不同的拥塞判断条件可以分为以下几类:
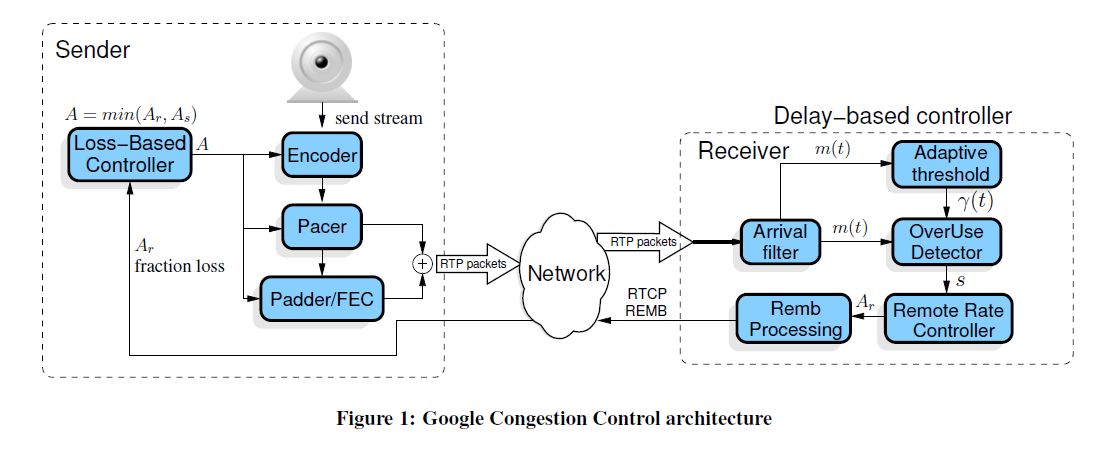
- 基于丢包:传统TCP框架是基于丢包的,因此TCP大部分算法都是以丢包为主,如reno,bic,cubic,webrtc中基于rtcp receiver report进行的发送端码率估计也是基于丢包的,此外还有非webrtc官方的webrtc支持的服务器的接收端码率估计一般也是基于丢包的(如KMS)。基于丢包的拥塞控制算法一般会引入较大的链路污染,其阈值估计会受bufferbloat影响。此外,在无线网络环境中可能存在随机丢包的场景,会严重影响TCP传输效率。
- 基于延迟:由于拥塞开始时,数据包开始在路由的buffer中堆积,因此数据传输的RTT在拥塞开始就会有直观的反应,因此使用延迟作为拥塞判断相对于丢包而言是更为准确的。但是也由于RTT变化先于丢包出现,因此在算法公平性上,简单处理(如vegas使用预期窗口差与一个固定期望值对比)将会导致基于延迟的算法最终被饿死,如最早提出的基于RTT的拥塞控制算法vegas。后续有部分基于vegas的衍生算法,如veno(算混合)和yeah,会尝试处理公平性及其他一些问题。此外,谷歌提出的bbr算法和用于webrtc中官方的接收端码率估计算法都是基于延迟的,gcc中使用了自适应阈值变化来解决公平性问题,而bbr则分为两段进行探测,一段探测RTT,一段探测BDP(对应buffer时候的场景)。
- 混合算法:由于tcp本身已经基于丢包实现,因此后续有不少拥塞控制算法只是单纯基于丢包,并在此基础上引入RTT来尝试解决TCP窗口控制的AIMD问题,比如应对无线网络中的随机丢包,会在丢包状态(TCP_CA_LOSS)下对RTT进行判断,来判断这个丢包是拥塞丢包还是随机丢包。
- 显式拥塞控制:现代路由可以支持显式拥塞控制标志,当路由检测到拥塞发生时,会在数据包上打上显式拥塞控制标志,当接收端收到这个标志的包时,会在ACK上打上对应的标志ECE,这样发送端就可以知道网络发生拥塞,这种是绝对的拥塞控制判断,其中tcp的data center tcp算法就依赖于数据中心交换机中的显式拥塞控制标志。
- 其他带宽估计算法:还有一些其他算法并不是使用于TCP,而是在一些偏实时通信上的,比如skype的sprout,基于统计学来对链路状态进行预估(TODO),从而估计出下一时刻的网络状态。还有FBRA(fec based rate adaptation),是在webrtc中提出的一种带宽估计算法,依赖于fec包的频率进行对应的码率估计与反馈。
- 自适应的拥塞控制算法:REMY文章中提出一种机器自己根据用户的网络链路状态(无线或者数据中心等)、使用场景(实时通信、文件传输等)来自动生成对应的拥塞控制算法。
拥塞避免算法的其他一些处理
- 丢包场景判断:如veno中,基于RTT对当前丢包的场景进行预估,如果RTT没有明显变化可以认为这个丢包是一个随机丢包。
- 平滑发送:为了防止某些时刻数据爆发发送而导致的瞬时拥塞,后续的一些拥塞控制算法都会使用平滑发送,如bbr,webrtc的gcc。
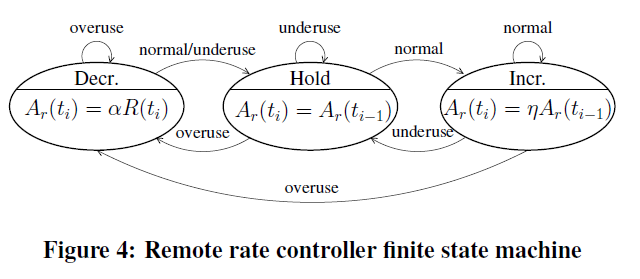
- 拥塞避免阶段的状态和吞吐量维持:即congestion_avoid模块,bic与cubic,以及webrtc gcc中的aimdratecontrol模块中,会在默认的阈值附近进行值的逼近,tcp部分算法会让tcp在拥塞避免阶段保持更长的时间,如bic与cubic,在拥塞避免初期会以更高的速度逼近阈值,而当靠近阈值时,会急速收敛,以非常小的增长速度去逼近阈值,超过阈值时也是以一个小速率增长,直到超过阈值一定范围后,会认为阈值估计不准,再次以较大的斜率进行增长,cubic中就是以一个立方根函数进行斜率控制,而webrtc中会根据统计学来维持阈值,并有一个kRcMaxUnknown可以标志当前阈值的有效性。
- RTT的精确计算:RTT的计算并不像丢包一样,丢了就是丢了,可能会在网络链路中存在传输时间的噪声,webrtc中加入了卡尔曼滤波来对观测值进行滤波,来获取更精确的RTT。
- 竞争流的判断:yeah算法会对进入拥塞状态进行统计,当连续进入拥塞状态,会认为此时正在和其他数据流共享网络资源,这时候会直接减半窗口大小(公平性),如果不是连续进入拥塞状态(拥塞状态会有恢复操作,如果是单独使用网络,而且跑到网络实际瓶颈,应该会在拥塞->恢复之间切换),说明此时只是跑到网络瓶颈,不需要像普通TCP一样对阈值进行剧烈衰减。
- 竞争流的贪婪性判断:yeah算法中有对reno算法进行模拟,并以reno算法的模拟值对竞争流的贪婪性进行判断,可以根据不同贪婪性竞争流对自己进行不同的拥塞控制。